



A computational framework of human voice production: from singing voice to pathological voice
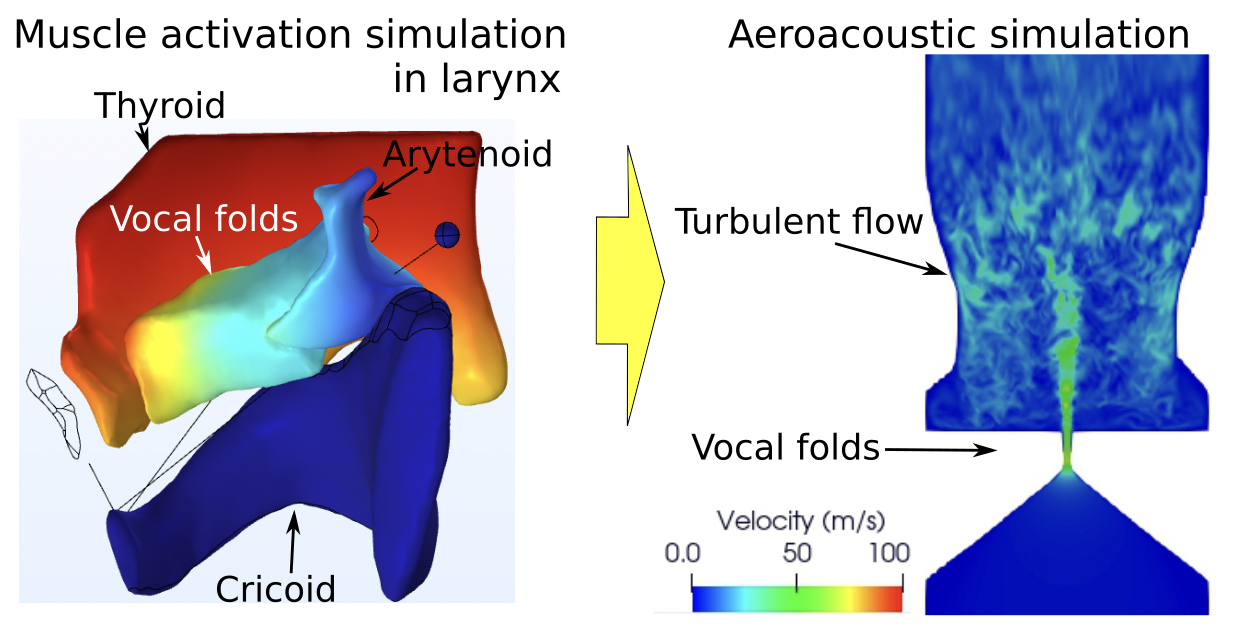
Human voice production is a complex process and requires fine coordination of different systems. Voice production starts with the airflow from the lungs, which excites the vocal folds into vibration and produces the sound source. The muscles around the larynx control the shape and tension of the vocal folds, thereby regulating the voice quality of the produced sound by the vocal folds. This sound then propagates through the vocal tract and is further shaped into different speech sounds by articulation of the tongue, lips, jaws, velum, and epilaryngeal structures. While the coordination of these different components makes it possible for humans to produce a large variety of voice types, particularly for singers, many questions remain as to how these different components interact to produce different voice types.
The goal of this study is to identify potential contributing factors to individual people’s unique voices at the physiological level. Due to limited access to the larynx and potential risks in human subject studies, we propose a computational approach to answer this question. We develop a computational model of muscular control of the larynx and tongue and fluid-structure interaction between the airflow and soft tissues in the larynx.
By using data from magnetic resonance imaging (MRI), computational simulations will be conducted to clarify how humans control their voices and investigate physiological parameters contributing to the production of different voice qualities, in normal speakers, trained singers, and patients. The success of the proposed studies will establish a computational framework answering fundamental questions about how humans produce and control voice, which has a broad impact on many disciplines, including linguistics, musicology, mechanical engineering, and head and neck surgery.
Author: Tsukasa Yoshinaga, Visiting Scholar and IDRE Fellow – Department of Head and Neck Surgery